Project Review: The Viral Texts Project
“The Country Editor–Paying the Yearly Subscription” by F.S. Church, from Harper’s Weekly (17 January 1874)
The Viral Texts Project was created to aid scholars in their understanding of how and why texts of the nineteenth century went viral. It seeks to uncover what texts were reprinted and why and which themes were widely consumed by audiences across the United States, Australia, and the United Kingdom. By examining textual and thematic qualities of news stories, short fiction, and poetry from nineteenth-century newspapers databases, the team comprised of professors and students from multiple Northeastern University departments present their findings in visualizations and interactive exhibits and in numerous publications.
This project is (was) planned to be conducted in multiple phases. In the first phase, the goal of Viral Texts was to develop a text finding algorithm they developed to sift through the thousands of articles in these databases for those that were reprinted by more than one publisher. Very few regulations were in place to prevent rival publications from “copying and pasting” interesting pieces into their own newspaper. Without these preventive measures, the algorithm can find which texts appear in different publications. This phase required two years of work, finishing in 2014. The second phase began in 2015 and piggybacked on phase 1 by taking the same algorithm and applying it to international reprinting of English-language newspapers. For this, they focused on the United Kingdom, Australia, and of course the United States. According to their website, future aims is to use this same process with non-English languages, particularly German. Unfortunately, the site does not seem to be updated often because Phase 2 is a proposal for the future years of 2015-2016.
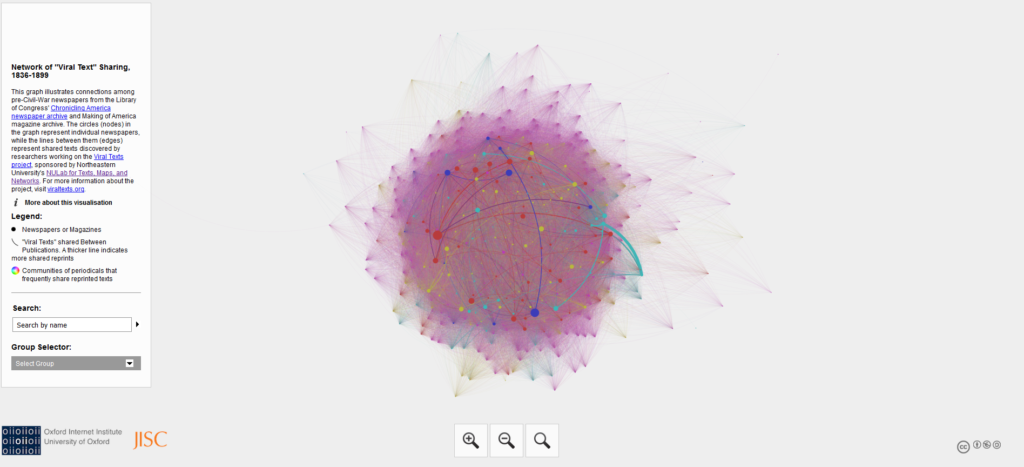
This mess of lines is the first visualization the team created. Network of “Viral Text” Sharing, 1836-1899 illustrates the different connections between pre-Civil War newspapers. They gathered the data from the Chronicling America newspaper archive from the Library of Congress which has created a searchable database of historic newspapers.
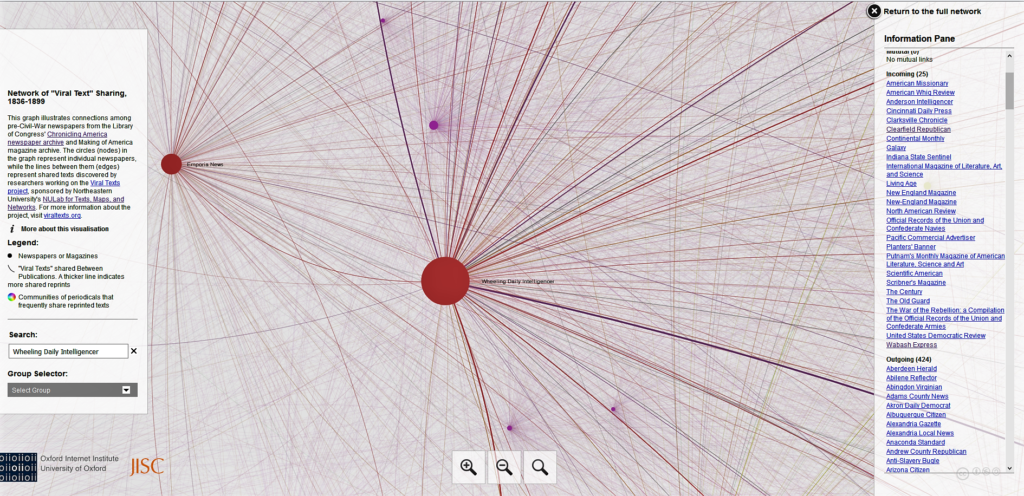
Upon closer inspection, users can navigate between each of the newspapers. Here we see the Wheeling Daily Intelligencer (1865-1903). According to the Chronicling America database, the Intelligencer was a West Virginia newspaper supported by Abraham Lincoln. It often called for the establishment of a non-slave state in western Virginia but its owner, Archibald Campbell, was a believer in free speech and allowed for the printing of opposing views alongside his own. After selecting a newspaper, links to any other paper copying stories is included as well as those brought in by the node.

The most interactive part of Viral Texts is “A “stunning” Love Letter.” Line-by-line of The Raftsman’s Journal for November 4,1868 has been annotated to allow users to select entire articles or individual lines and see other newspapers where they were published. This level of interactivity is much easier to follow than the Network of “Viral Text” Sharing, 1836-1899 because it does not present large amounts of tangled information immediately. This exhibit is much more suited for the public who can sift through the information at their own pace. The lines (edges) connecting the nodes in the Network can seem daunting at first glance and has the risk of intimidating people.
Unfortunately, Viral Texts relies heavily on providing links to outside databases, archives, and other websites to prove their argument. While this is great method of exploration for users in the beginning, time has a way of messing with the interactivity. Many of the links found within “A “stunning” Love Letter” do not exist anymore. Over the seven-years that this project has existed, these links no longer exist. The amount of work required to keep a project such as this up-to-date is substantial; we see evidence of this on the front page which has not been updated in years. I imagine the reason for this is because a large amount of the labor involved in this has been students. As they leave school, they no longer can commit to helping with Viral Texts and the workload is shifted to the two professors who started the project.
Overall, Viral Texts has the makings of being a wonderfully interactive website which can be useful to historic paper researchers as well as the public. In a day in age where we see virility constantly, it is interesting to see how it played out in a non-digital era. With some updating, Viral Texts can continue to be a useful resource for all.
The Viral Texts Project. https://viraltexts.org/. Created by Ryan Cordell and David Smith and maintained by Co-PI Ryan Cordell. https://viraltexts.org/index. Reviewed Feb. 3, 2019-Feb. 4, 2019.
2 Comments
Maeve Kane
That’s a great point about the broken links, bring that up in class. Do you think there are any alternatives that would have prevented that?
John Epp
The only method I can personally see is to check your site frequently. By the looks of it, this site does not seem to have been updated much since ~2014. As Dan mentioned in class today, money is everything. Universities and institutions that have access to a seemingly endless amount of money have the ability to assign people to update projects semi-regularly. If I had to venture a guess as to why there is link rot here, I would say it is because most of the team is (was) comprised of students. As they move on, they no longer work on the project.
A quick Google search suggests using archiving services such as WebCite to preserve these pages. I don’t have any experience with this so I don’t know how successful it is.