-
Great Lakes Shipwrecks (1679 – 2005)
Welcome to Jack Grobe’s Shipwreck Data Analysis Project (1679 – 2005). In this project, I have set about cataloging information about shipwrecks in the North American Great Lakes. Below you can find maps and various data visualizations about these wrecks, along with descriptions with hyperlinks to Wikipedia articles for further context.
-
-
Shipwreck of the Week: Maitland (1871)
#Spaming the class with posts today, but I’m trying to be productive on my sick day. For the first wreck, I’m going to discuss the S/V Maitland: a three-masted barque sunk in a collision with two other ships!

“Two?!?” -
Mapping Great Lakes Shipwrecks Progress Post
I have been chugging away on the project. This weekend, the main two things I worked on was data cleaning the build information to produce the Build Location map for the wireframe as well as continuing to add Latitude and Longitude to my entries.
-
Mapping Great Lakes Shipwrecks Wire Frame
This project is mapping the wrecks of the Great Lakes. For the purposes of this project, a shipwreck is a vessel that has experienced an incident that has placed it out of commission. Because of the incident logged within, the vessel never sailed on its own again. This can mean the ship was sunk, or damaged beyond ability to repair and return to service.
-
Jack’s Shipwreck Project
Introduction
This dataset is a collection of data on shipwrecks in the Great Lakes. My project proposal is to complete a Tableau map and data analysis of the wrecks in Lake Ontario. So far, there are 313 wrecks in the dataset for Lake Ontario, with data on each along 76 different columns of information. Currently, I am data cleaning rows to update the information and add in LAT/LON information for mapping, there are about 20 rows left to clean. Along the way, more wrecks might yet be added to the Lake Ontario dataset as I consult updates to sources. I have already had to take out some wrecks that were erroneously recorded as in Lake Ontario, but which actually occurred elsewhere (F. A. Georger)…
-
Introduction to Networks: Church Congregation 1735-46
In the first few years, the groups of the congregation do not seem to interact much, until 1738. The more years that are added up until 1745, the larger that the networks grow (unsurprisingly). This demonstrates that the congregation is expanding with time. This growth can be explained as either a growth in the size and interactions of the community as a whole or the church in particular. Either way, this growth is possibly demonstrating a time of peace or expansion. Before the data is seriously manipulated, John Wemp and Mary Butler appear to be the biggest nodes.
However, upon examination (with more colors added in), other connective nodes are apparent. Filtering by betweenness seems to decrease the size of nodes, as compared to filtering by year. By comparison, cluster comparisons were closer to the look of the by year filtering.
Anna Clement seemed to play a large role in connecting the two subgroups of the church together when the data is viewed by clustering as opposed to the role played by Aron Oseragighte and Cornelius Thanighwanege on the by year view. Other figures who play a larger role as explored on the clustering tab are Peter Young, Isaac Wemp, Abraham Canostens Peterse, and Cornelius Brown.
The various view point and manners of data organization allow for examinations of inter-personal relationships. The clustering and other views, allow researchers to view groupings that might not be readily apparent in more traditional forms of research scholarship.
-
Cartograms & Bar Charts
Cartograms
Cartograms are a type of data visualization that can help historians to display comparative data. Taking the glancing appearance of a map, cartograms are a data visualization that display as an altered map, in which the typical basis of display (land area) is altered. Ordered loosely by geographic locale, cartograms allow historians to view data loosely based on geography, yet altered to assist in digestibility or to display comparative values. Below is an example of the former:
-
Shipwreck Dataset
The dataset selected was my shipwreck dataset that I have been compiling for about 15 years now. Each row represents a different shipwreck, of which there are about 400. The wrecks are ships gone missing and never found, wrecks found on the bottom and not identified, and combinations of the two. Each column, for a total of about 77, is a different set of information about the ship. Information is contained about the ship, the sinking, and the wreck. There is build info containing the time, place, and builder. There is a section on the dimensions and tonnage of the ship. Then ownership and registry info. Information about the final trip, the cause of sinking, an the general circumstances regarding the sinking. The scope of the information right now is confined to Lake Ontario as the other wrecks have been placed into a backup tab, so I can focus on a smaller subset to work with for now.
The data was generated by a combination of primary sources and secondary. Primary information comes from vessel registration documents and from newspapers clippings (digitized in the Maritime History of the Great Lakes dataset). The secondary sources consist of datasets like Bowling Green University’s online database of ship registry information or historian David Swayze’s shipwreck list on the Boat Nerd site. These are coupled with non-online sources like diving guides and archeological surveys. The dataset has been reworked and expanded several times to accommodate new information and columns like “homeport”.
-Jack Grobe
-
Mapping the Republic of Letters Review
Mapping the Republic of Letters. http://republicofletters.stanford.edu/#. Stanford University? http://republicofletters.stanford.edu/contact.html. February 04, 2019.
Mapping the Republic of Letters is a huge dataset of primary sources and accompanying digital analysis. I cannot overemphasise the sheer size of this project. It is overseen by three persons, with a total of sixteen distinct contributors. Of those, three have contributed to more than one subproject, with the highest being three. There are 12 subsections, with each subsection of a case study containing as much information as the Pox Americana digital project. To call this a single project is a bit misleading as the various subprojects have certain levels of distinctiveness, betraying their creation by different scholars.
This project functions both as a digital narrative/database as well as a digitalized archive. The primary documents present are comprised of correspondence, travel logs, and notes. Not all three are available for every person studied however. These are paired with secondary digital analysis, spatial maps and neural networks, of the intersections between these collections and thinkers. Frequently, comparisons are made to other subprojects (ex: mapping Voltaire’s network as compares to Lockes).
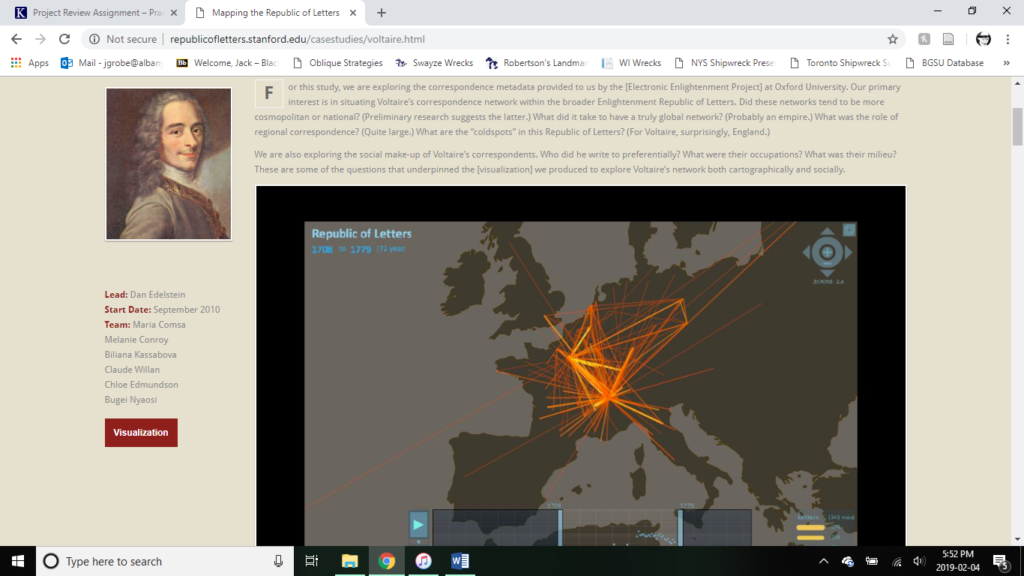
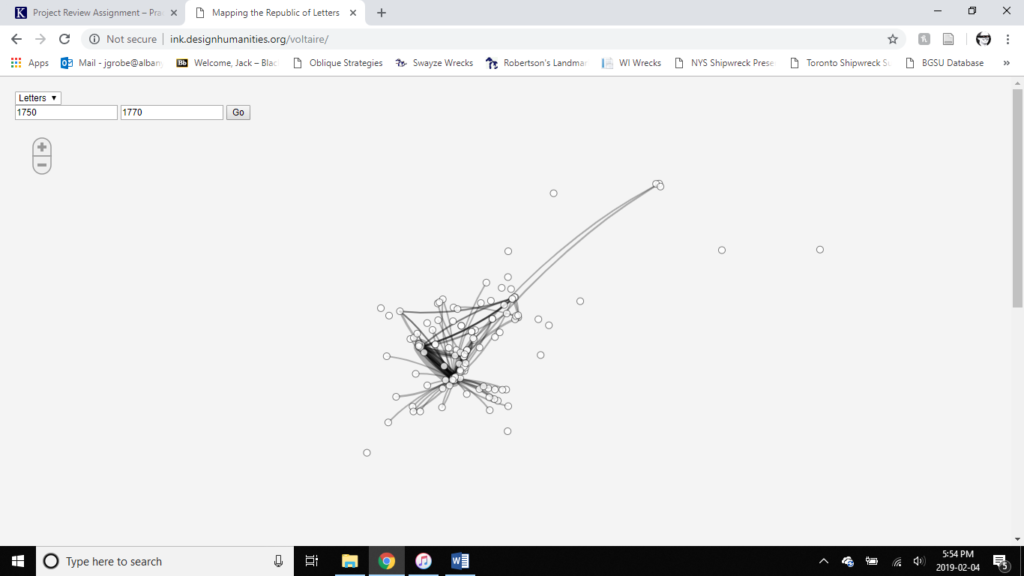
The overall project seems to be aimed at a scholarly audience. The amount of information contained is larger and more detailed than the average passing viewer is interested in as well as too bulky for a teaching aid in a classroom. The premise of the database is to reinforce the importance of social networks among intellectuals at the time as well as mapping out the intersections of thought and correspondence. There is also not a ton of interactive material, as pages exist mainly to subdivide the material into more easily consumable chunks. Some sections attempt to be interactive, but page errors like a failure to render a map or link dots with presentable info prevent this:
Navigation on the site is clear enough, with archival materials and analysis being presented in three categories being on the type of primary document being utilized: Correspondence, Publications, and Travel. The thinkers can not be grouped by nationality or subfield.
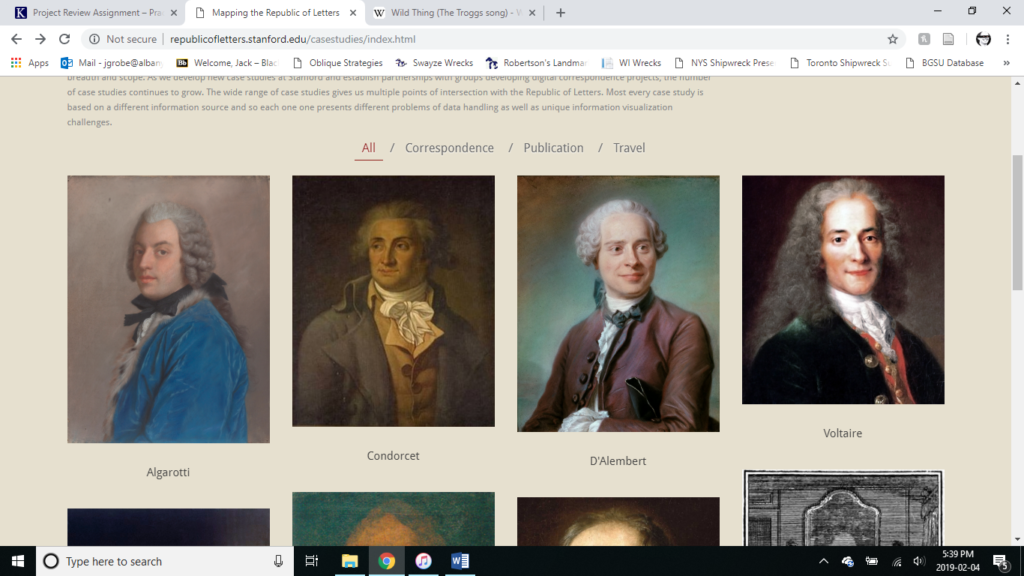
Despite the organization, it is very easy to get lost on the site given the huge amount of material. There are records available for intellectuals of England/the United Kingdom, France, Italy, and Spain. Records refer to other locations (like Italy) in the context of visitors to there from one of the three main empires studied. English thinkers are best represented along with the French. Spain is presented as a single entity without being broken down into individuals. Notably missing are Dutch, German, and Eastern European thinkers. The lack of the latter is understandable due to issues of preservation, but where are the Dutch like Antonie van Leeuwenhoek?
In the end, given the massive size and detail of this project and its subprojects, Mapping the Republic of Letters appears to offer itself most easily to scholars seeking to understand networks of thought and communication during the Age of Discovery. The amount of digital mapping of both spatial distance of correspondence as well as neural networks of correspondents is displayed most easily in a digital format. The maps could be printed off and consumed offline, but lack of interactiveness notwithstanding, this project is most easily consumable in a digital format.
This massive undertaking provides invaluable information and analysis for scholars studying the thinkers and intellectual networks of the Age of Discovery. With the addition of Dutch, Portuguese, and other passed over thinkers, this project will only become more valuable.